Introducing SHARPlib
In the process of preparing for my talk at the 2024 American Meteorological Society meeting in Baltimore, I realized that I had a lot more I wanted to say and a lot more context about the design choices made in the process of this project that just did not fit into a 15 minute talk. I have a post I’ve been wanting to write for some time about the case for blogging again in 2024, but we’ll save that for another time, and instead just say this felt like the perfect medium to share this kind of information. I’ve also been secretly working towards building this site to be a bit more of a digital playground for myself and my projects… What do you think of the place so far? It’s a little bare bones in my opinion, but it has potential. That’s not why you’re here though - so let me talk to you about what I’ve been working on at the Storm Prediction Center for the last year and a half, and introduce you to SHARPlib. It’s a work in progress, but it’s already supporting some cool projects, and it’s time for its introduction to the wider world.
A Decade of SHARPpy
You probably have some questions, such as "Isn't SHARPpy a thing? Why isn't it being updated as frequently? Isn't a new library a bit redundant?" - all of which are perfectly fair and reasonable questions I hope to address! However, to adequately answer those questions requires some retrospective. You see, this year marks 10 years since an overly enthusiastic Freshman/Sophomore undergraduate student found the dormant skeleton of a GitHub project Dr. Patrick Marsh announced in January of 2012 known as "SHARPpy''. This student had very little clue about a lot of things, but he was a little dangerous with Python, and Patrick had laid out a pretty robust scaffold. What could go wrong? By January of 2015, myself and my wonderful collaborators Dr. Greg Blumberg and Dr. Tim Supinie presented a mostly-complete version of the software, and had published our BAMS article by 2017. Since then, SHARPpy and its initial presentation have received over 150 citations for studies it's either supported or been evaluated by. It's seen use within local National Weather Service Forecast Offices, provides Skew-T and Hodograph plots for several major numerical weather model forecast websites, has seen use at international institutions such as the Australian Bureau of Meteorology, has seen use within the US Navy and US Air Force, and has been used by many teams in the field to display and process mobile radiosonde data for various NSF funded field campaigns. All in all, it succeeded in its mission - replicating and democratizing the tools used by SPC so that others may benefit from the incredible work the forecasters have put into this specialized tool.
While by all measures a success, SHARPy is not without its deficiencies. Over the last decade of using SHARPpy, seeing how people interact with and use software, and bettering myself as a software developer and scientist, there are a few lessons learned that I think are worth sharing.
- Don’t let a sophomore undergraduate write your mission critical software.
- Joking aside, I was completely blind to what I didn’t know, and everything looked like a nail that needed an Object Oriented hammer.
- Replicating a tool without understanding the underlying decisions and challenges facing that tool can have consequences.
- Maintaining open source software is hard.
- Open source maintainers often deal with limited funding (if any at all), limited time, and limited resources.
- It’s really hard to cover everyone’s specific use cases.
- Users of open source software don’t know what they don’t know, which can cause friction. I’ve been guilty of this…
- Open source software is incredibly powerful.
- None of SHARPpy’s success and adoption would be possible without being open and accessible to the widest user base possible.
- Extra pairs of eyes on your code can be incredibly helpful for catching bugs and issues.
- SHARPpy tried to be too much at once, and that makes it hard to maintain.
- It’s a number crunching library for sounding based analysis
- It’s a data visualization toolkit for severe, winter, and fire weather.
- It’s a data management engine for:
- Radiosondes
- Point forecast soundings (including ensembles)
- Gridded WRF NetCDF output
- Polar orbiter data via NUCAPS (recent!)
- Python is a powerful language, but it isn’t the right choice for everything.
- Analyzing gridded datasets with SHARPpy is absurdly slow. Want to run it on the HRRR? Hope you can outlive the heat death of the universe!
- Dependency and version management (especially outside of Conda) can be brutal, and doubly so with graphics APIs/libraries.
Three Decades of NSHARP
When I joined SPC in the fall of 2022, it provided an opportunity to address some of the outstanding issues with SHARPpy mentioned above. After all, part of the reason behind hiring me (as was communicated to me at the time) was to help take over maintenance and development of NSHARP from the forecasters. Before diving right in and tackling that task, however, I needed to spend some time understanding the needs and requirements of SPC, its IT/Sys admins, its forecasters, and its management. You see, NSHARP (and its various forms) are more core to SPC operations than most people realize - and it's important to continue to keep it healthy, maintainable, and accessible to a wide range of use cases. Much of the innovative research produced by the forecasters at SPC has come through the ability to quickly iterate and experiment with NSHARP in an operational setting, and it became abundantly clear that preserving this should be the primary focus of any rewrite or refactor going forward. So, in the process of fixing some outstanding bugs and issues with the various forms of NSHARP, I also spent a lot of time talking to John Hart, Rich Thompson, and many of the other forecasters about their reasonings behind certain decisions, things they'd like to see changed going forward, and things they'd prefer to not see changed. Here's some of what I learned through that process...
- Performance for interactivity and timely products matter
- Nobody likes using sluggish software.
- Timeliness of mesoanalysis products impacts watch/mesoscale discussion time scale.
- Reliability and consistency matter
- Forecasters are well calibrated to both the raw input data as well as numerical output.
- Increasing amounts of SPC data are being fed to AI/ML guidance.
- Maintaining multiple versions of the same software is challenging.
- NSHARP, its research variant SHARPtab, the SPC web graphics, and the SPC mesoanalysis were all independent code bases.
- The ability to quickly implement current research into operational workflows can have positive outcomes on the forecast process.
SHARPlib: Understanding Requirements
So if it isn't clear already, SHARPpy wasn't a suitable replacement for NSHARP going forward, but SPC needed to start thinking forward on how to uncouple the code from legacy GEMPAK/N-AWIPS routines it was built to interface with, among other things. In performing this evaluation, however, it spelled out a pretty clear list of criteria to consider moving forward. Requirements include:
- It must be performant for raw observed radiosonde data (~3-6k vertical levels)
- It must be performant for gridded mesoanalysis and model data processing
- It should limit scope to core set of utilities
- It should be able to integrate with multiple languages
- Operational code at SPC is often in C and FORTRAN
- Science Support Branch (SSB) use cases are often written in Python or Javascript
- It needs some form of automated known-value testing.
- It needs to lay a foundation for several more decades of experimentation and innovation.
So, considering the need for high performance, multiple language and platform compatibility requirements, and the desire to cut down on duplicate code, I personally felt like C++ was the appropriate language for the task. To some, that will sound entirely too bleeding edge and complicated for non-experts to use. Others might object for modern pushes towards more memory safe languages such as Rust. Some will still say that I should’ve chosen FORTRAN instead… but hopefully some of the reasoning below can convince you that C++ really is the tool for the job.
C++ isn’t going away anytime soon.
C++ is a language really well suited towards performant algorithms and algorithm development, especially with its comprehensive Standard Template Library (STL) that contains just about any data structure you could want or need. In fact, it’s probably even over engineered for the task. Importantly, a lot of the underlying software in AI/ML libraries use C++ or CUDA C++. Libraries in this space are not likely to disappear any time soon, and C++ is mature enough as a language to have lots of legacy code and platform support on a wide array of compute hardware. In short: people in 30-50 years will most likely still be using or supporting C++ software unless there’s a fundamental revolution in quantum computing or something. Which, who knows, it could happen. Or we could all die by then. It’s 50/50, really. If you don’t believe me about C++ still existing in 30 years, all I ask is you look at the amount of legacy FORTRAN code used across scientific disciplines.
C++ has powerful tools for code reuse.
One of the more powerful features of C++ (admittedly also its most powerful foot gun) is its support for compile time template meta programming. If that sounds like a bunch of jargon, it’s because it mostly is - template meta programming is effectively the offloading generic code for the compiler to figure out how to handle at compile-time. You write code that writes code! A great example might be finding the minimum and maximum value over some layer. In this case, the algorithm is effectively the same: a linear search over some range, and you change the comparison operator in order to get the minimum or maximum value. In this example, you might have the functions find_min and find_max. Instead of having two different functions, you can create a generic function that takes in the comparison operator as an argument. At compile time (with a few caveats not mentioned), depending on where the function calls are and what the arguments are, the compiler will generate the correct code at compile time, meaning that you only have a single function you have to maintain: find_minmax. It is highly recommended that you use this functionality sparingly and with careful thought, however, because it can result in some very challenging debugging if you are not careful. This is powerful for two primary reasons:
- Reduction of duplicate code by generalizing certain algorithms.
- Offloading comparison operations that might be expensive to conduct within iterative loops to the compiler.
- This is case dependent, however, as CPU branch prediction algorithms are pretty darn good. Compilers are often better programmers than humans, and if you think there’s a performance issue, the first thing you should always do is construct a test. Don’t over optimize something without testing first, or you’ll likely make your code slower and harder to understand.
C++ can interface relatively easily with other languages.
Lastly, I think it’s really important to mention the flexibility of C++ in interfacing with other languages. It often isn’t pretty, and requires the addition of some additional template code to interface with external languages, but sometimes it’s a better alternative to maintaining separate versions of the same library. Out of the box, C++ can compile (and link to) any existing C code natively, which is pretty cool. It requires the use of some wrapper code, but you can also call C++ code directly from C! Using C as a bridge, you could even run C++ code in FORTRAN. I have no idea why you would want to do that, and it comes with some costs, but it’s cool nonetheless. Some other cross-language communication can be enabled using:
- Simple Wrapper Interface Generator (SWIG) bindings for Python, C#, Go, Java, Javascript, Perl, R, and many more languages.
- Web Assembly (WASM) and Javascript bindings using Emscripten (NCSA).
So, while there is some bias from experience using C++ in my thesis work, that work involved solving a lot of problems that also needed solving here. It’s stable, mature, powerful, and its features enable many useful workflows for developing and maintaining this kind of code. This can come at the cost of some complexity for compiling and maintaining the code, but relative to the existing legacy libraries, these tradeoffs are mostly positive. C++ compilers are also natively shipped on most systems we work with, making it an easy choice. Perhaps in another 10 years I’ll view things differently, but I at least feel confident in the analysis that’s led to these decisions thus far.
SHARPlib: Initial Release Status
I’ve spent an awful lot of time explaining the ‘why’ and ‘how’, but there are some of you who are more concerned with ‘what’ and ‘when’. While at this point in the article such information may be more lean than desired, this has been quite a lot to write, and there’s no better way to learn about something than giving the tires a good kick and taking it for a spin around the block. I’m happy to report that thanks to the awesome management at the Storm Prediction Center, an early preview, in-progress release of SHARPlib is available as of the publication of this article. Once again, this is an experimental, preliminary, early release, personal copy of a forthcoming official version from NOAA/SPC. Expect breaking changes, unstable APIs, and some minor friction for folks not as adept at the command line. With that said, I’d estimate that the various components range anywhere from 75%-90% completion. It’s suitable enough that we are going to be using SHARPlib this spring for portions of the Hazardous Weather Testbed Spring Forecast Experiment (HWT SFE), and it is my belief that achieving the final 10-25% of completion left can only come from using the library and finding out where the rough edges are. We are early enough in the development process where I feel comfortable making changes if it becomes apparent that certain decisions need revising, while stable enough in its functionality that you can largely expect the library to look and behave as it is now.
Current features:
- C++17 compatibility baseline
- RHEL8 or newer equivalent C++ compilers (GCC >= 8.0 or Clang equivalent)
- CMake >= 3.1 for building
- Fully wrapped Python API with native NumPy support.
- SWIG >= 4.1 required
- Fully wrapped C API
- Some initial coverage of unit and performance testing
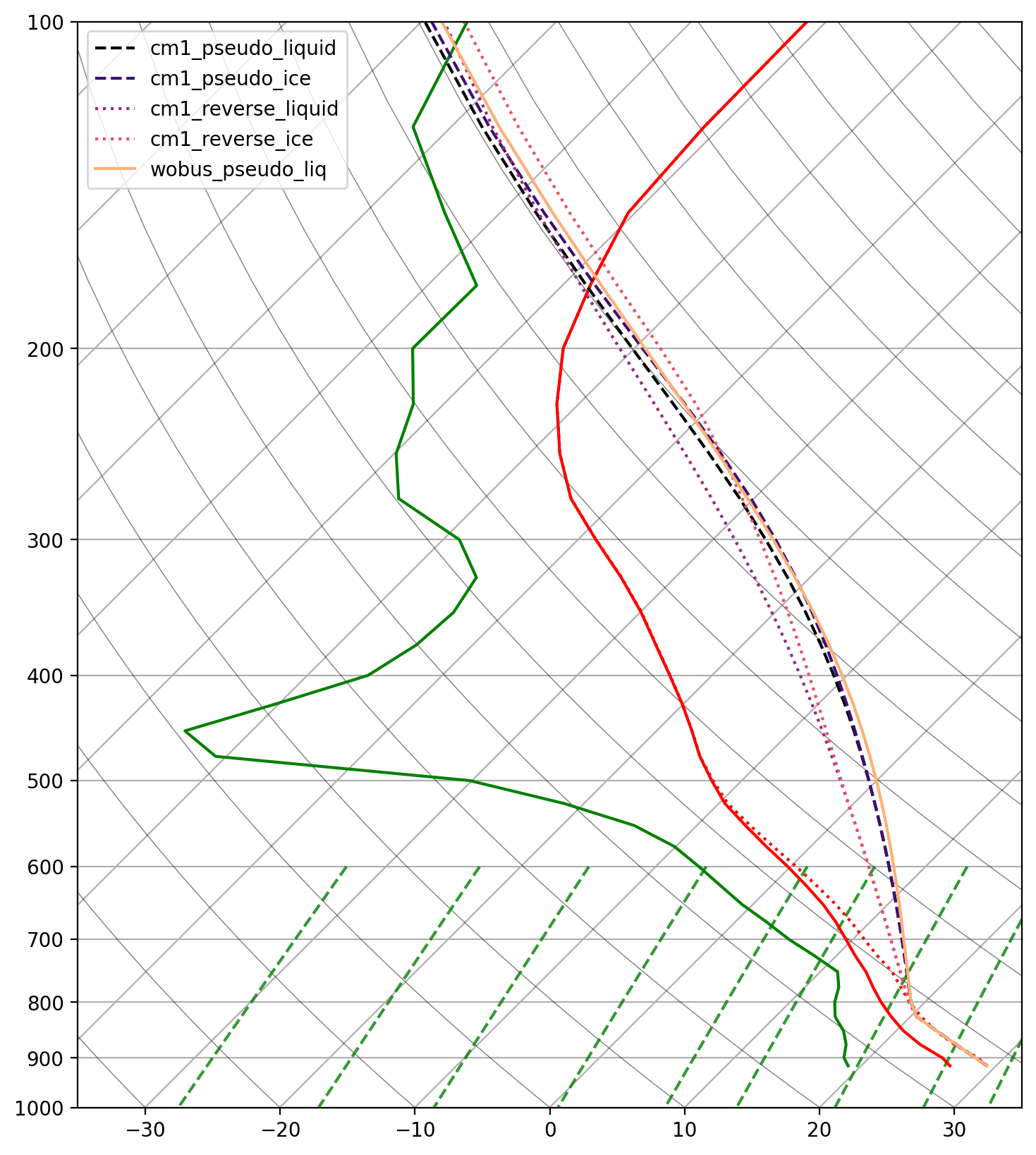
- Configurable moist adiabats for parcel based ascent
- Wobus liquid-only pseudoadiabats (current SPC/SHARPpy default)
- Bryan and Fritch 2004/CM1 ice-liquid potential temperature adiabats and pseudoadiabats
Planned features:
- Javascript and WebAssembly support (through either Emscripten or SWIG)
- Performance improvements to existing CM1 adiabatic ascent
- Current implementation was targeted towards replication, but was not necessarily implemented in a performant way. It’s the consequence of trying to port code before you fully understand it.
- More configurable moist adiabats
- Davies-Jones 2008 (MetPy default)
- Peters et al. 2022 (parcel ascent with entrainment of dry air)
- Flesh out the remainder of derived severe, winter, and fire weather parameters
Parting Thoughts
If you’ve made it this far, I just want to say I do sincerely appreciate your attention. While I have yet to show you any actual code in the process of getting here, I did feel it important to properly document the thought processes behind the decision making leading to this point - not only for posterity, but more than likely, there are others in our field who struggle with similar challenges and may not be aware of some of the available tools and solutions to meet those challenges. In the future, perhaps I will do some demo blog posts that are more hands-on with walking through code and processes. If that’s something you would be interested in, please let me know by dropping me an email or a mention on the platform formerly known as Twitter. I have yet to flesh out how I want to handle comments on blog posts for this website, so until I do, that is the best way to get in contact with me.
I’m excited about the future projects and scientific analysis this new library will help enable by lowering the barrier to performant analysis of larger datasets. We have plans to use SHARPlib for upgrading the SPC Mesoanalysis, upgrading NSHARP’s ability to process raw-resolution radiosonde data and ensemble forecast data, and robust analysis of storms and their environments over a multi-decade period. I’m also really encouraged by the robustness of the existing SHARPpy and NSHARP routines, because while there have been numerous bugs addressed that were previously unknown, statistical analysis against a large number (> 200k) of atmospheric profiles shows that on the whole, distributions of calculations have not dramatically shifted from what is expected. If you’re interested in knowing more about that, I recommend checking out the slides or recorded talk of the presentation at AMS.
Lastly, I wanted to set some expectations about the level of support for this library. Unlike with SHARPpy, this library is an official part of my job duties and will continue to be for the foreseeable future. We are thrilled to make this available as open source for the wider atmospheric science and meteorological communities, as we’ve seen first-hand just how powerful it can be to have this kind of software that supports open and reproducible science. However, I cannot personally guarantee that I will always be able to meet your specific issues and requests in a timely manner, and those requests and issues may not align with the goals and missions of SPC. Therefore, we are approaching this more like a benevolent dictatorship. If we don’t meet your needs, take it and do something wonderful - or, better yet, get in the dirt and grit and make a pull request on GitHub. Don’t be shy, this all started because of an overly enthusiastic student who got bored! Just be warned - you may back your way into a career and be left carrying the torch when I’m finished :).
Acknowledgements
Thank you John Hart for your incredible patience and kindness as I not-so-delicately dove head first through your decades of hard work, blood, sweat and tears. My goal and hope is to make sure that work lives on for many decades to come, and you’ve been an invaluable resource not only to me, but the larger community as a whole. Thank you Rich Thompson for the many lively discussions and brainstorming sessions about how to tackle aspects of these challenges, and for giving an over eager student the time of day and attention all those years ago. Thank you Nathan Dahl for your hard work in helping me reach the finish line significantly faster than I could alone by tackling many of the missing parameters and features I had yet to address. Thank you to Greg and Tim for the help in getting SHARPpy off the ground - it’s forever changed my career and you are both responsible for that! Finally, thank you to the management at the Storm Prediction Center (specifically Patrick Marsh, Israel Jirak, Russ Schneider, Bill Bunting, and Matthew Elliot) for your support, guidance, insight, and trust in me to make this happen.
Cheers,
Kelton.